TOC
為什麼我想寫這個主題系列文?
近幾年,AI 模型從 paper 中躍進於各產業中,但當模型訓練好後,工程師常常會陷入一種狀況,我要怎樣呈現模型現在的好壞?怎樣評估我的模型可以上戰場?
如果跟 paper 一樣,把所有可以用來評估 AI 模型效能的指標,一股腦地全部放上來,有時候,資訊越多,反而越難做決策,所以我腦中一直在思考,是否有一套具有邏輯性的流程來闡述分類型 AI 模型的效能?
最近在工作上,有機會接觸到 FDA 的相關文件,看到了文件中所闡述各種 AI 模型的指標後,加上過往的工作經驗,讓我理出了一些頭緒,想透過這篇文章跟大家分享與討論。
評估分類型AI效能的三個面向
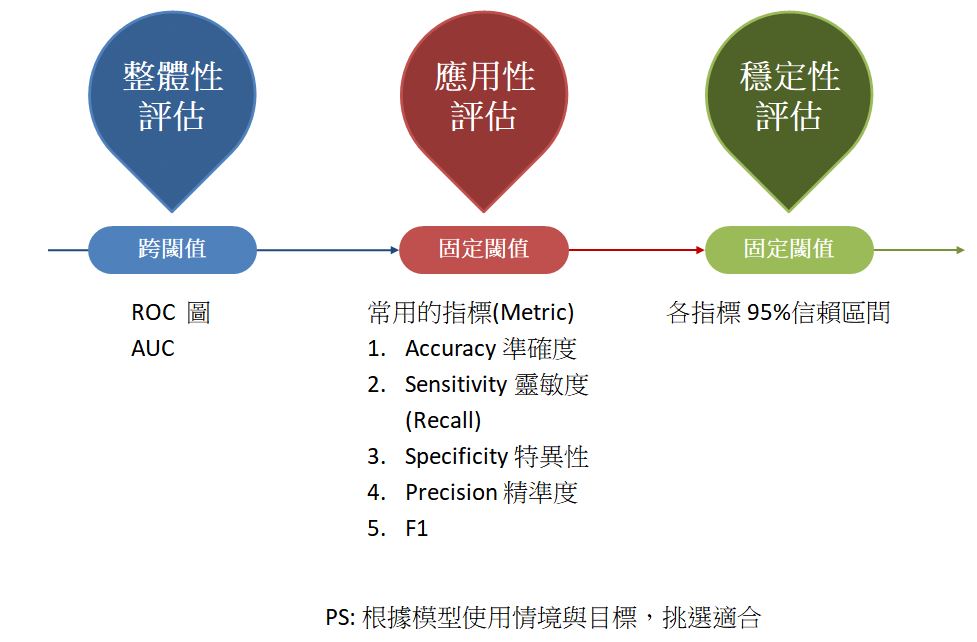
評估分類型 AI 模型的效能,應該具有這三個面向,包含整體性評估,應用性評估與穩定性評估,這三個面向在呈現上是有其順序性的,
1.整體性評估: 透過呈現 ROC 圖與 AUC 數值呈現模型的整體狀況,同時可以比較自家模型和其他模型的優劣。
2.應用性評估: 透過固定閾值的方式,來計算相關指標,如準確度,召回率等,實際說明 AI 模型實際應用後,使用者會實際感受到模型的狀態。
3.穩定性評估: 最後搭配信賴區間,說明不同的測試資料集上,上述指標的變動程度,來說明模型實際上線後模型指標的可能變化範圍。
評估分類型AI三面向
接下來系列文中,將分為三個部分,我將循序漸進,從應用性評估開始, 透過例子依序介紹。
介紹分類型 AI 模型常用的指標與應用的情境,讓使用者能根據需求挑選適合的指標呈現。
切入整體性評估,來說明 ROC 圖與 AUC 是什麼,FDA 文件中,分類型 AI 模型的 AUC 的下限為多少?
最後, 你一定感覺上述的指標說明模型就足夠了,為什麼還需要信賴區間的資訊? 最後一篇,將說明什麼是信賴區間,以及為什麼信賴區間可以說明明模型上線後的穩定度。
你對這個系列文感興趣嗎?